What is a Support Vector Machine?
Most neophytes, who begin to put their hands to Machine Learning, start with regression and classification algorithms naturally. These algos are uncomplicated and easy to follow. Yet, it is necessary to think one step ahead to clutch the concepts of machine learning better.
There are a lot more concepts to learn in machine learning, which may not be as rudimentary as regression or classification techniques, but can help us answer different intricate cases. So, today let us get familiar with one such algorithm, the Support Vector Machine or SVM.
What is a Support Vector Machine? Let us walk through.
Support Vector Machine
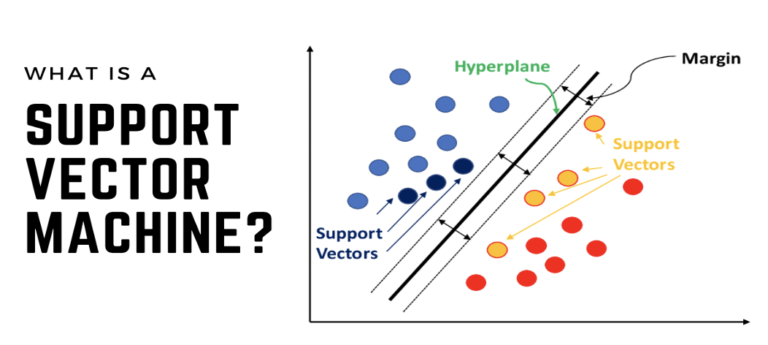
Support Vector Machines or SVMs are supervised machine learning models i.e. they use labeled datasets to train the algorithms. SVM can work out for both linear and nonlinear problems, and by the notion of margin, it classifies between various classes. However, in essence, it is used for Classification problems in Machine Learning. The objective of the algorithm is to find the finest line or decision boundary that can separate n-dimensional space into classes such that one can put the new data points in the right class in the future. This decision boundary is called a hyperplane. In most of the cases, SVMs have a cut above precision than Decision Trees, KNNs, Naive Bayes Classifiers, logistic regressions, etc. In addition to this SVMs have been well known to outmatch neural networks on a few occasions. SVMs are highly recommended due to their easier implementation, and higher accuracy with less computation.
Based on the training sets, SVM are basically of two types-
- Linear SVM – Data points can be easily separated with a linear line.
- Non-Linear SVM – Data points cannot be easily separated with a linear line.
Now, in the next section, we will look forward to the working of SVMs.
How does SVM Work?
Before delving deep into the working of SVM, let us quickly understand the following terms.
- Margin – Margin is the gap between the hyperplane and the support vectors.
- Hyperplane – Hyperplanes are decision boundaries that aid in classifying the data points.
- Support Vectors – Support Vectors are the data points that are on or nearest to the hyperplane and influence the position of the hyperplane.
- Kernel function – These are the functions used to determine the shape of the hyperplane and decision boundary.
Linear SVM
We will try to understand the working of SVM by an example where we have two classes that are shown below.
Class A: Circle
Class B: Triangle
Now, the SVM algorithm is applied and it finds out the best hyperplane that divides both the classes.
SVM takes all the data points in deliberation and produces a line that is known as ‘Hyperplane’ which segregates both the classes. This line is also called ‘Decision boundary’. Anything that will fall in the circle would belong to class A and vice-versa.
There can be more than one hyperplane but we can find that the hyperplane for which the margin is maximum is the optimal hyperplane. The main objective of SVM is to find such hyperplanes that can classify the data points with high precision.
Non-Linear SVM
A Kernel function is invariably used by Support Vector Machines, even if the data is linear or not, but its real robustness is leveraged only when the data is inseparable in its present form.
In the instance of nonlinear data, SVM makes use of the Kernel-trick. The intention is to map the non-linearly separable data from a lower dimension into a higher dimensional space to find a hyperplane.
For example, the mapping function transforms the 2D nonlinear input space into a 3D output space using kernel functions. The complexity of finding the mapping function in SVM reduces significantly by using Kernel Functions.
Moving forward we will look at some of the applications of SVM.
Applications of SVM
SVM has got employment across numerous regression and classification real-life challenges. Some of the fundamental applications of SVM are given below.
- Classification of text/hypertext
- Image classification
- Classification of satellite data such as Synthetic-Aperture Radar
- Classifying biological substances like proteins
Pros of SVM:
- It is efficacious for problems where the number of dimensions is greater than the number of samples.
- It works well in cases with a clear margin of separation.
- It uses a subset of training points in the decision function (support vectors), which makes it memory efficient.
- It is effective in high-dimensional spaces.
Cons of SVM :
- The performance is not so good when the data set is large because the time required for training is more.
- It doesn’t provide probability approximates.
- It fails to perform when the data set is noisy.
Conclusion
In this blog, we have made an effort to answer the question, ‘What is a Support Vector Machine?’ We learned that the SVM classifies the linearly separable data into different classes by finding the most appropriate hyperplane, else we can use the kernel trick to make it work if the data isn’t linearly separable. Lastly, we came across the advantages and disadvantages of SVM along with some real-world applications of support vector machines.
Datatron works hard to enable businesses to deploy ML models efficiently so that they can focus on the organization’s most pressing problems to make data-driven decisions.
Datatron, our model governance, and management platform provides an enterprise-grade platform that helps you to supervise your Machine Learning models for high precision deployment to meet the regulatory requirements and effective management of the entire production machine learning life cycle.
Follow us on Twitter and LinkedIn.
Thanks for reading!