MLOps: Flexible & Simple
Automated
Model Deployment
Catalog, Deploy, Monitor, & Govern Models via Cloud, On-prem, or Build Your Own via API

What is MLOps?
Machine Learning Operations (MLOps) provides end-to-end capabilities for deploying, managing, governing, and securing machine learning and other probabilistic models in production.
MLOps is a framework for managing machine learning and applying DevOps principles to accelerate the development, testing, and deployment of AI/ML models. Its goal is to help organizations conduct continuous integration (CI/CD), development, and delivery of AI/ML models at scale.
Challenges
Artificial Intelligence / Machine Learning (AI/ML) is delivering significant impact to businesses. Some of the largest tech companies in the world are already using AI/ML to achieve operational efficiencies and profit.
With demonstrated use cases of success, businesses in all sectors are expanding use of AI/ML for competitive advantage against rivals. Executives are forced to decide to build in-house or leverage external tools (e.g., time vs. money), among other challenges. Unfortunately, close to 90% of such AI/ML projects fail to deliver the promised ROI.
Why is this? The largest tech companies know early on the importance of the underlying infrastructure and automation support to properly operationalize AI/ML projects. However, most other businesses only hear of the benefits of AI/ML without appreciating what is required to empower these projects to be successful.
This is where Datatron’s robust set of MLOps features help enterprises’ AI/ML programs succeed.

MLOps Features
Any Language, Any Framework, Any Library
Data scientists have the flexibility to utilize the best languages, libraries, and frameworks to build the best models. Even within the same organization, different business units will benefit from using the frameworks that are best suited to tackle specific business challenges than others.
With data scientists free to build models the way they need to, not only will businesses realize true ROI, but data scientists will be substantially more productive.
Actionable Model Catalog
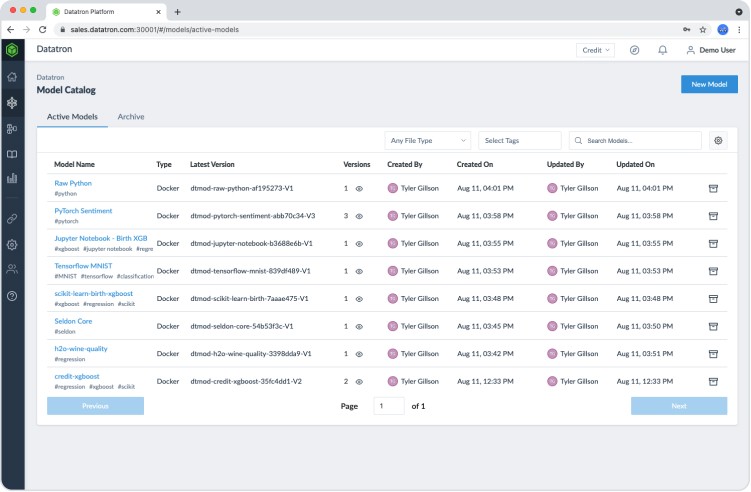
More than a registry of AI models, Datatron’s Actionable Model Catalog provides the ultimate model transparency and lineage throughout the AI model’s operationalization, monitoring, and governance lifecycle.
When models are first registered, Datatron’s Model Catalog will automatically capture the properties, metadata, and more and populate the detail throughout the system.
Every time a model is uploaded, Datatron’s Model Catalog creates a model version by giving it a unique identifier. Complete archives of all models uploaded under this particular model name are shown in the user interface (UI) with details, such as: created at, created by, updated at, updated by, model name, version number, metadata, tags, model locations, input and output features, and more; allowing for teams to find relevant models in the catalog quickly.
This feature also allows customers to trace back to when the exact model was used and which dataset it was built against.
Multiple Deployment Models
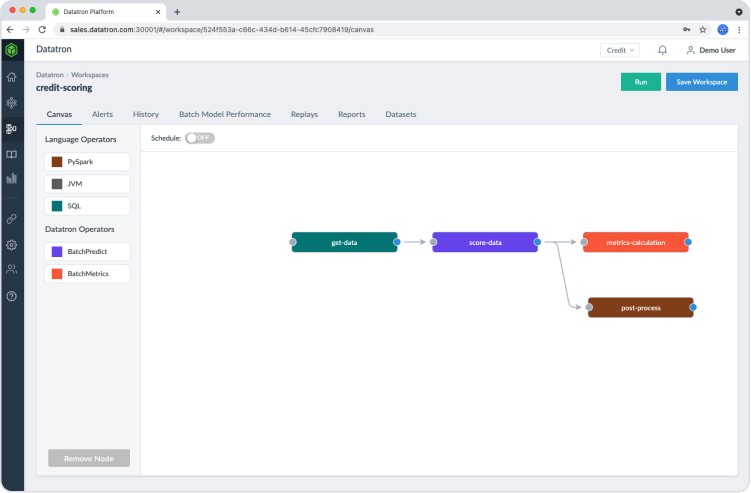
Real-time Interference – Support models for inferencing with real-time and streaming data.
- Batch Scoring – Allows you to score models on very large datasets offline. You can build sophisticated workflows that include pulling and joining data from multiple sources and storing the output to a designated location.
- High-performance – Whether for Real-time Inference or Offline Batch Scoring, Datatron applies advanced high-performance parallel processing to handle large datasets. Not only does this significantly accelerate data processing speed, but it also reduces/optimizes compute infrastructure.
Publisher/Challenger Gateway
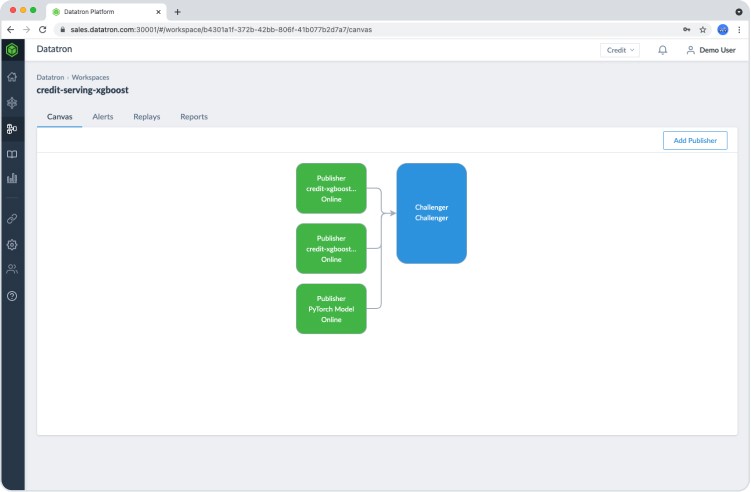
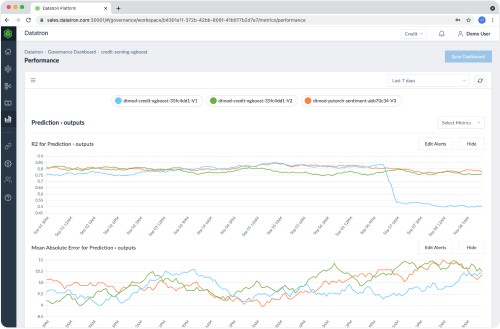
Datatron’s patented Publisher/Challenger Gateway is uniquely designed to rapidly iterate on multiple models at the same time without having to deal with the complex handshake and change management process between the data scientists and the application team.
Furthermore, Datatron’s gateway allows models to leverage real-world production data as a final validation before being pushed into production.
- A/B Testing – Perform A/B testing on model sequences, rather than just on particular models. Set up the static and dynamic model sequence with the advantage of conducting sequencing and A/B testing simultaneously.
- Canary Mode – Directing a very small stream of live traffic to the new models allows you to catch and fix bugs and to gauge model performance quickly and early, without impacting the application.
- Shadow Mode – Setup new models to run alongside existing models using the same production data without affecting the application that is servicing real workload, eliminating guesswork on whether new or updated models will be as effective as the current models.
- Failover Mode – Models do fail while running in production for a variety of reasons. Datatron allows you to configure a failover model to take over if the primary model does not perform within a certain set of criteria.
Model Rollback
Datatron’s model rollback feature allows you to revert back to the last successful model version and deployment run. This can be done whether it is related to deployment failures, incorrect code commit, incorrect model version deployed, if the model was trained on the wrong dataset, and more. Rollback prevents you from further problems incurred for a variety of reasons.
GPU Support
In addition to the ability to utilize CPU for processing, if it is available in your environment, you can utilize GPUs for models that require high-performance processing – giving you the flexibility you need to ensure the optimal resource allocation for suitable business use cases.
Parallelization and Distributed Computing
Leveraging the latest technologies in parallelization and distributed computing, models can take advantage of the unique properties of AI models, whereby distributing computing architecture built into Datatron will enable the most optimal performance regardless of hardware resources.
Model Rollout
Depending on how large the production cluster is and how complex the business logic behind the infrastructure, you can choose among different types of deployment options. These options include:
- One at a time
- Half at a time
- All at once
In some cases, it might be better to deploy a new version by bringing down the entire cluster all at once, allowing the infrastructure to have downtime. In other cases, the cluster might need to stay up for the entirety of the application, and therefore partial deployment might be desirable.
“Why Data Scientists Love Datatron”
Problem
After formulating and rigorous testing of AI/ML models in the lab, models must be deployed to production to deliver real business value. However many challenges await:
- What if models don’t perform in production as they do in the lab?
- Without the right team, are Data Scientists forced to moonlight as AI/ML DevOps Engineers to operationalize models?
- Who will maintain these models and monitor for bias, anomalies or drift?
Solution
With Datatron, Data Scientists can focus on producing more models, while the efforts of AI/ML DevOps Engineers are multiplied, as they can support more models with the same level of effort. The Platform is development environment agnostic and can support models developed in any environment. Additionally, Datatron monitors Models for irregularities.