Confusion Matrix Metrics
Now that you understand the general structure of a confusion matrix as well as the associated key terms, we can dive into some of the main metrics that you can calculate from a confusion matrix.
Note: this list is not exhaustive — if you want to see all of the metrics that you can calculate, check out Wikipedia’s page.
Accuracy
This is simply equal to the proportion of predictions that the model classified correctly.
Precision
Precision is also known as positive predictive value and is the proportion of relevant instances among the retrieved instances. In other words, it answers the question “What proportion of positive identifications was actually correct?”
Recall
Recall, also known as the sensitivity, hit rate, or the true positive rate (TPR), is the proportion of the total amount of relevant instances that were actually retrieved. It answers the question “What proportion of actual positives was identified correctly?”
To really hit it home, the diagram below is a great way to remember the difference between precision and recall (it certainly helped me)!
Specificity
Specificity, also known as the true negative rate (TNR), measures the proportion of actual negatives that are correctly identified as such. It is the opposite of recall.
F1 Score
The F1 score is a measure of a test’s accuracy — it is the harmonic mean of precision and recall. It can have a maximum score of 1 (perfect precision and recall) and a minimum of 0. Overall, it is a measure of the preciseness and robustness of your model.
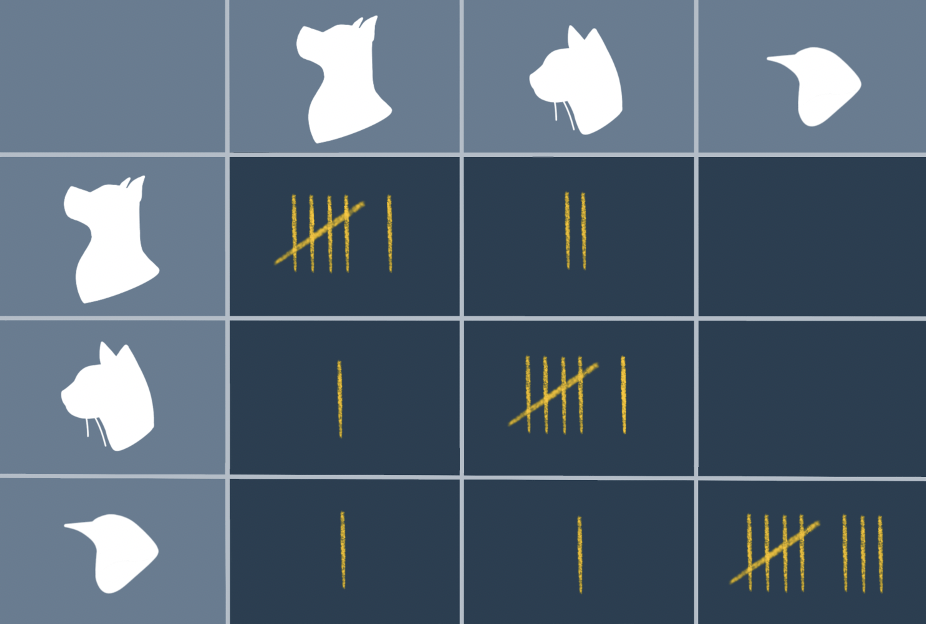
Example of 2×2 Confusion Matrix
If this still isn’t making sense to you, it will after we take a look at the example below.
Imagine that we created a machine learning model that predicts whether a patient has cancer or not. The table on the left shows twelve predictions that the model made as well as the actual result of each patient. With our paired-data, you can then fill out the confusion matrix using the structure that I showed above.
Once this is filled in, we can learn a number of things about our model:
- Our model predicted that 4/12 (red + yellow) patients had cancer when there were actually 3/12 (red + blue) patients with cancer
- Our model has an accuracy of 9/12 or 75% ((red + green)/(total))
- The recall of our model is equal to 2/(2+1) = 66%
In reality, you would want the recall of a cancer detection model to be as close to 100% as possible. It’s far worse if a patient with cancer is diagnosed as cancer-free, as opposed to a cancer-free patient being diagnosed with cancer only to realize later with more testing that he/she doesn’t have it.
Python Code
Below is a summary of code that you need to calculate the metrics above:
# Confusion Matrix
from sklearn.metrics import confusion_matrix
confusion_matrix(y_true, y_pred)
# Accuracy
from sklearn.metrics import accuracy_score
accuracy_score(y_true, y_pred)
# Recall
from sklearn.metrics import recall_score
recall_score(y_true, y_pred, average=None)
# Precision
from sklearn.metrics import precision_score
precision_score(y_true, y_pred, average=None)
There are three ways you can calculate the F1 score in Python:
# Method 1: sklearn
from sklearn.metrics import f1_score
f1_score(y_true, y_pred, average=None)
# Method 2: Manual Calculation
F1 = 2 * (precision * recall) / (precision + recall)
# Method 3: Classification report [BONUS]
from sklearn.metrics import classification_report
print(classification_report(y_true, y_pred, target_names=target_names))
Conclusion
Now that you know what a confusion matrix is as well as its associated metrics, you can effectively evaluate your classification ML models. This is also essential to understand even after you finish developing your ML model, as you’ll be leveraging these metrics in the model monitoring and model management stages of the machine learning life cycle.
Here at Datatron, we offer a platform to govern and manage all of your Machine Learning, Artificial Intelligence, and Data Science Models in Production. Additionally, we help you automate, optimize, and accelerate your ML models to ensure they are running smoothly and efficiently in production — To learn more about our services be sure to Book a Demo.
Thanks for Reading!