
MLOps: 5 Common Pitfalls and How to Overcome Them

Not the pitfall you were expecting? They rarely are.
Tell me if this sounds familiar. Your company decided to use data to solve a problem but new problems arose immediately. Your data scientist looks into the tools required and sends you the information. Between the cost and the headaches associated with getting approval, you all but decided to scrap the whole idea. Then comes the miracle: open source. No cost requirement. No approval is needed. Just take it and run with it.
Your data scientist builds the model, trains it, tests it, takes it on playdates with other little models, and decides it’s ready to unleash on the big, bad world. You start using it immediately but the results aren’t what you’re expecting. You talk to the data scientist and they say, “Everything still looks fine, check with the ML Engineer.” You check with your ML Engineer and they assure you that everything is fine. A bit later, you tell your data scientist that it isn’t working right so you’re pulling the plug on this model but maybe the next one will be better. Your data scientist goes back to the lab and builds the next model.
The cycle repeats. After the fourth time or so, the data scientist is frustrated because all the models they’ve built aren’t staying in production. Your ML Engineer has lost all semblance of sanity. Your executives throw their arms in the air, exasperated at the entire situation.
Have you lived through this? It’s pretty rough for all parties involved. It’s even worse if you can’t properly articulate what went wrong. We’ve heard every flavor of this story from prospects, customers, and practitioners alike. That’s what we’re going to discuss today. This article will go over the common problems when building an MLOps solution (homegrown or open-source) for your data departments and how to solve them.
Issue #1: Models Built In Different Libraries/Languages/Stacks

“What do you mean, these need to fit together?”
Your data scientist built the model in Python locally. Your developers use Kubernetes through AWS. Neither works properly with your application without significant tweaking. The exact tools and languages might differ but the point is that building the pieces of your AI/ML program without ensuring they will work with each other means your deployment will be significantly hindered due to reworks.
It might be tempting to say, “Okay, why not just have all of the teams use the same language and framework?” That might work but it isn’t necessarily efficient. One issue is that most people have a preferred way of working; for instance, preferring Python over R or Scala. Another issue is efficiency. There’s a saying a mentor once told me about Python: “Python is the second-best language for everything.” What he meant is that Python can do just about anything and can do it pretty well but there is a language that is better at doing any particular task than Python. For the smaller projects, this is a fairly negligible difference, but for tasks that do millions of iterations over trillions of data points, a 5% (arbitrarily chosen) increase can be the difference between your model giving you results in time or being a day late and a dollar short.
Solution: Use a solution that supports any model built on any stack. Empower your data scientists to build the best model using the right library, language, or stack for the job.
Issue #2: Scaling AI/ML = Scaling Staff to Support AI
If we hire any more people, we might need a bigger office.
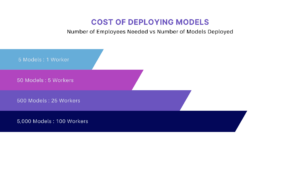
I don’t know how recently you’ve tried to acquire top-level talent but there are a plethora of openings and not near enough talent to fill them. As you grow your AI/ML program, you’ll probably need to find more people to maintain the models. If your data scientist is both an all-star and willing to do the DevOps side, you might be able to get a handful of models in deployment just by employing just one person. Your data scientist probably doesn’t prefer the DevOps – I know that I don’t – meaning they’re hoping you spring for an ML Engineer or a DevOps person. By the time you deploy around 50 models, you need a minimum of 5 employees working full-time to deploy the models. The more you grow your AI/ML program, the more talent you’ll need to maintain it.
Many companies don’t want to invest in a new department without an ROI already being established, and again, unless your data scientist also moonlights as a DevOps, you’re going to run into issues with deployment immediately. Worse, you’re going to have to convince the powers that be to hire a new person while those issues still exist because the ROI won’t happen while the issues exist. If you can’t hire a person until the ROI exists and can’t generate an ROI until you hire a new person, you create a catch-22 that will lead to frustrations department-wide.
On the note of the shortage of talent, while you’re trying to fill that DevOps position, your all-star data scientist gets a call offering them their dream job and a 13% pay bump. All that knowledge and versatility? Gone. All the crafty tricks of the trade that your models required? Happily being put to work on a different model. Brain drain can cripple an entire department if proper precautions aren’t taken.
Solution: Use a solution that minimizes the human cost while maximizing the ROI and that allows a successor to work expertly with what their predecessor left.
Your Models Deserve Liberation.
Datatron MLOps is the Answer.
Issue #3: Models Requiring Dynamic Endpoints

Keys, keys everywhere, yet not one of them works.
Your new data scientist figured out a great new feature that gives you a 10% boost in model performance. They coded it expertly, integrated it with the model, and passed it to the deployment team. The deployment team pushes it into production and immediately everything grinds to a halt. What gives?
Every time a new model is deployed or a new version of a model is released, the endpoint that the API calls needs to be changed. If you forget to change even one of those call points, the code will not work. Ask any coder, from someone just learning to code to someone who has created a new language, what happens when you forget even a quotation mark. Like before, with a smaller project, changing the endpoints isn’t a big deal, but if you have hundreds or thousands of locations relying on your model to give them vital information, even before considering that models have a lifetime and are constantly being revised, changing them individually is untenable.
Solution: Use a solution that removes the need to update endpoints.
Issue #4: Lack of Support

Don’t worry, they’ll get to you eventually. Probably.
There are impressive open-source tools but what if you need them to do a little bit extra? Your DevOps found a stopgap answer on a message board but it isn’t quite perfect. Worse, it can’t integrate into the actual deployment itself, so anyone that uses it has to update their API call. Still worse, many of the people who use your model didn’t check their email so you’re fielding lots of calls that start with, “My program isn’t working.”
You try to call the open-source provider, but given the number of companies and individuals using it, there’s a substantial wait time. When you are finally able to talk to someone, they tell you that they aren’t able to support the additional code. You ask for them to incorporate this new capability and they tell you that they’ll look into it. If they do, it’s likely going to be at the end of a long list of capabilities they’re hoping to add. If you are the only one who has asked for it, it might never make it to the drawing board.
Your DevOps team feels deflated; why try to innovate if it’ll never see the light of day? Your data team worries about trying new things because they aren’t sure that the new features will integrate with the open-source tools. Your end-users are still waiting for this new thing.
Someone on your team comes up with a great idea: why not build a platform internally? You run the numbers and, oh boy, between the amount needed just to invest in the tools, server space, and individual talent to build, you inadvertently let out a chuckle that dashes the hopes of the team member.
Solution: Use a solution that makes time to work with you and that will implement the capabilities you want to see.
Issue #5: Lack of AI Governance

I feel like this was important… Oh well.
Remember that feature that your data scientist added in point three? There have been claims that it’s biased against a particular group, so Legal reaches out for the documentation. Does your team still have the data that was used to train and test it originally?
They do? Great. They run the verification tests again and find no evidence of bias during the initial integration. They run the same verification tests against the current data and find that, sure enough, that bias exists. Do you have the data used for each version after the original? Were there any changes between then and now? Who made those changes?
Version control is a painstaking endeavor that requires meticulous recordkeeping. It’s also an area where “I don’t know” isn’t an acceptable answer. Traceability is also an important factor as it can tell you if additional training or other measures might be necessary to correct any errant behavior.
Legal tells you that you can’t use the model. DevOps tells you that the original model won’t work now. If you don’t have the versions between the initial deployment and now, you have to scrap the old model and build a new one from scratch.
Solution: Use a solution that catalogs all previous versions of the model and all of the data used to verify it, allowing you to revert to any previous version if needed.
Does any of this sound familiar to you? Does all of it? Oof. That’s a rough go of things. Don’t worry. We’ve seen everything mentioned above and have a singular solution for all those problems. Interested in seeing how our unique platform tackles them? Schedule a demo. We’d love to talk to you.
About Datatron
“The Datatron” is a flexible MLOps & AI Governance platform that helps you deploy, catalog, manage, monitor, & govern your ML models in production (on-prem, in the cloud, or integrated feature-by-feature via our API). Datatron supports any model built on any stack, including, SAS, H2O, Python, R, Scikit-Learn, TensorFlow, and more. Executives get a high-level overview of every BU and model via the “Health Dashboard.” A single ML Engineer can manage, version, monitor, and deploy 1,000’s of models at scale for the entire company via the model catalog, and our patented static endpoint ensures models deploy without issue. Data Scientists can monitor models for bias, drift, KPIs, & performance anomalies via real-time alerts, helping determine root causes before issues become costly GRC problems. Risk & Compliance teams receive standardized audit reports across regions. Fortune 1,000 companies like Comcast, Domino’s, and the top bank in Switzerland, along with early AI programs looking to build AI right, and mature AI programs circling back to correct homegrown infrastructure deficiencies are choosing Datatron to accelerate the ROI from AI. Datatron is Reliable AI™.
