
3 Dirty Secrets of MLOps – The Hidden Costs of Open Source Software & Big Cloud
A Guide for AI Executives to Accelerate ROI from AI/ML and Avoid Common Delays
The proverbial “best practices” dust is settling in choosing a tech stack for Machine Learning. And it isn’t a total Open Source Solution (OSS), or all-in with “big cloud.” The unanimous evolved best practice in ML is a “hybrid” approach. I’ll explain more about the hybrid approach, but first, let’s explain how we got here.
1. You Don’t Know, What You Don’t Know (and what your MLE doesn’t want to tell you)
Your data science and ML engineering team has come to you with a proposal – they are going to build your entire ML stack on top of open source. “Look at all the benefits”:
- * Zero capital cost (Free)
- * Bypass the laborious and bureaucratic vendor approval process
- * Tools for just about every possible feature need
- * Customizable code
It seems like a slam dunk. So the team goes off and toils away at stitching together what should be the ideal solution at a great price. Weeks, months, and maybe even years go by. Models are developed and trained, but consistently fail to be deployed reliably and sustainably. You realize it was heavy on promise, but light on planning, and you are not getting ROI from AI. Your data scientist is frustrated that their models are not in production. The ML Engineer swears they can fix it, buying more time, which you cautiously allow. Wash. Rinse. Repeat. This cycle goes on and on. Sometimes under the veil of secrecy, sometimes out in the open. But the “promise” of your low/no cost open source ML stack keeps hope alive, even if the reality is far from it.
(And yes, the same can occur to a lesser extent on Big Cloud as well, which we’ll cover in the next section.)
Figure 1. Shows a theoretical example stack with OSS tools for each function, which was assembled at mymlops.com. There is no indication of the level of complexity at getting these disparate tools to play nice with each other or if they will. (MLOps roulette anyone? Do you really want to have to manage, update, and support all these tools?)
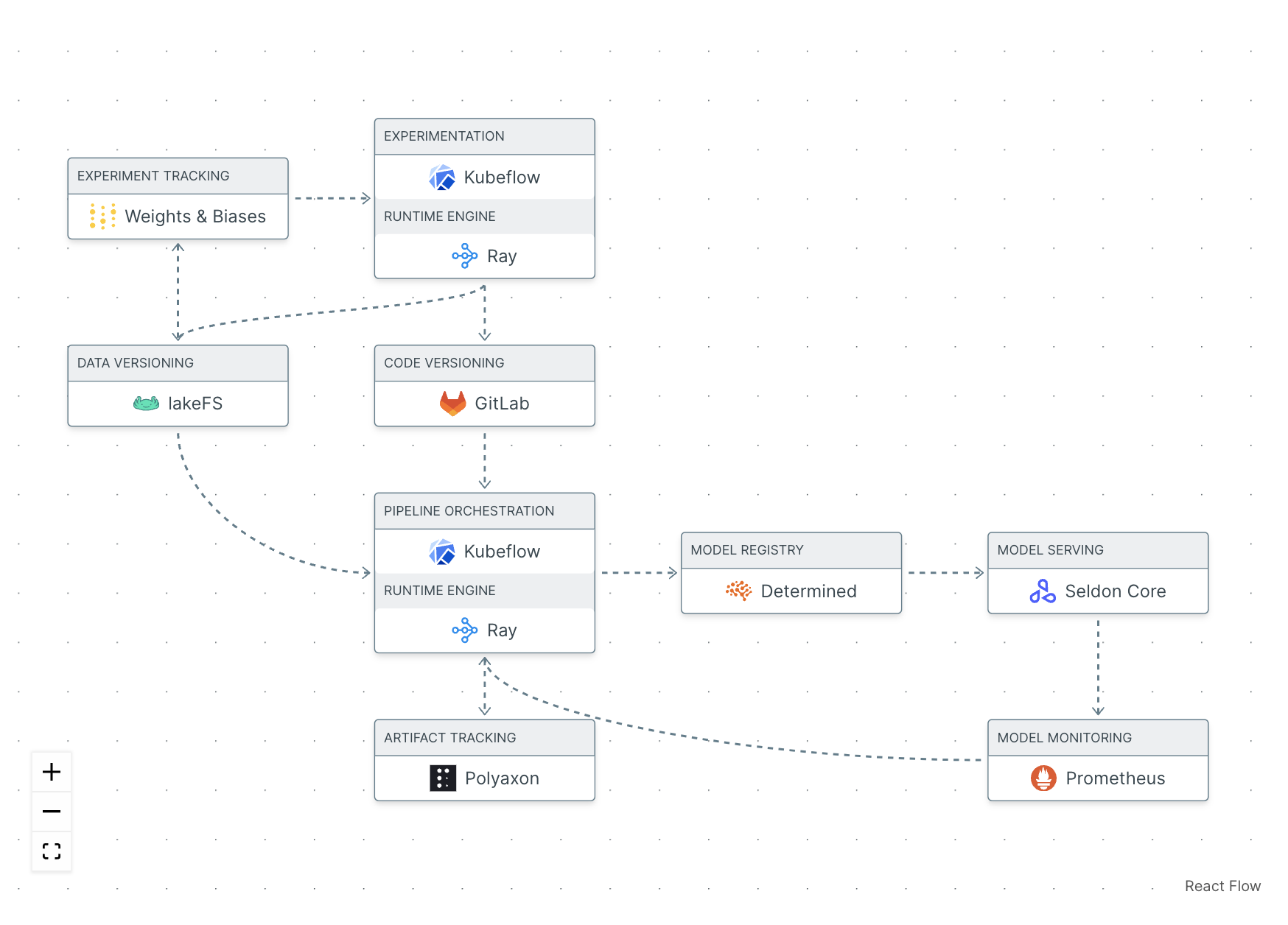
Figure 1. A hypothetical example MLOps stack assembled at MyMLOps.com
Solution: In addition to setting a hard deadline for “Go Live” of your homegrown MLOps, it is CRITICAL to set a deadline for deploying your first model to production. If you don’t, you’ll lose critical time in getting value from ML – while competitors that avoid this make gains.
2. Going Down the Rabbit Hole. Welcome, Alice! – Plan or Plug’n Pay
You’ve decided to go all-in on OSS or big cloud. Congratulations on making a tough decision. Now you can focus on getting value from ML. But there’s no “perfect” vendor or tool in OSS or big cloud, and compromises need to be made, but it can get even worse. Let’s talk about each of these:
OSS
Like a kid in the candy store, making a selection with so many shiny tools to choose from and so many tradeoffs, it’s difficult to balance. Compromise is inevitable. Your team has an immediate need, so they select what they believe to be the best OSS tool for that job. Great. Next challenge. Again, they select what they believe to be the best solution, and since they are open source, they all connect relatively seamlessly. This is called the “Falling Forward” strategy. Several tools later, your workflow is coming along nicely, with each tool doing its intended function. And then, “Houston, we have a problem.” It appears that you (and your team) have grossly underestimated the operational complexity required to keep a system like this up and running.
Figure 2. Below demonstrates all the moving parts required just to deploy a model to production post-development and neither OSS nor big cloud will handle all of this auto-magically.
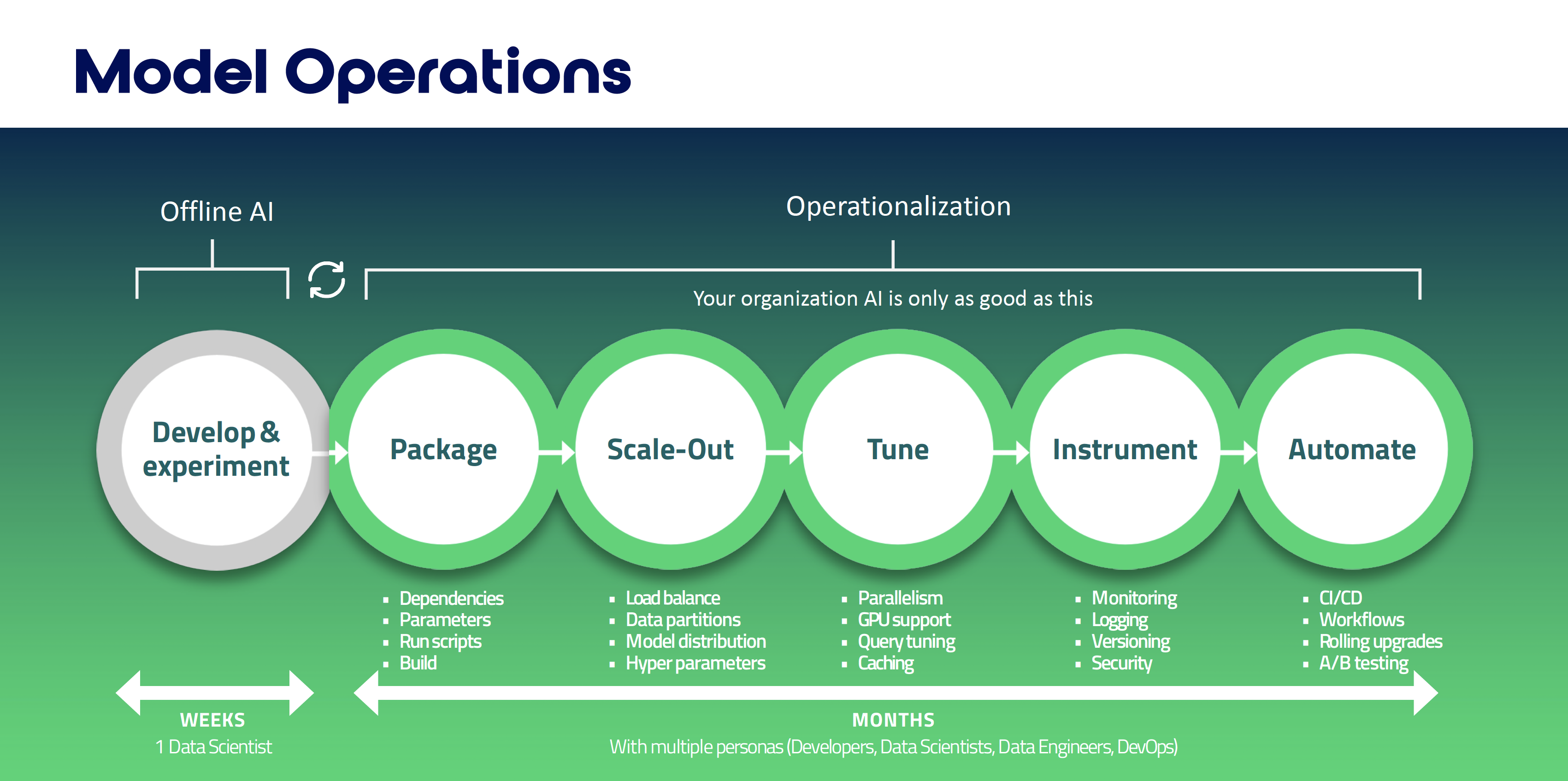
Figure 2. The five stages of “Operationalization” and all of the complex sub-tasks required to operationalize a model into production
You now have a tool that is not reliably delivering business value from AI/ML. Your team is fatigued (and may even start leaving). You’ll need to start over, or at least exhaust countless resources to remedy this.
Big Cloud
Your big cloud sales rep has promised their offering will be the panacea that you crave – an all-in-one solution (heck, they’ve even thought of things you haven’t even pondered before, AKA “shiny objects”). How could it go awry?
Once the ink is dry on that sizable contract and your tech resources dig into the myriad of offerings, they slowly make a discovery. This isn’t quite the IKEA experience you all thought it was – you aren’t getting laser-cut parts, the exact hardware, and simple-to-follow instructions necessary to EASILY assemble the components into a usable solution. Quite the opposite, in this analogy, you are getting the raw material of wood, and pig iron, and that’s it (those illustrated Lego instructions are nowhere to be found).
Again, proper planning would have helped, but overcoming some chasms is part of the process.
Solution: Spend more time planning to understand the dependencies before you begin. Try out tools that offer a free SaaS trial so you know what you are getting into (the LOE of this may seem high, but not compared to the painful alternatives). If you are already knee-deep and need to re-tool, acknowledge and accept it (no shame, only bruised egos here), then watch this video to help kickstart your thinking on how to plan:
Part XI: Advice for Early AI/ML Programs from Domino’s & Datatron – MLOps & AI Governance Webinar
3. Customization Leads to Institutional Knowledge Exiting with (Inevitable) Team Attrition
Whether you are stitching together an OSS solution, or building on top of Big Cloud, there’s bound to be some customization. In fact, the more customized the solution (vis-à-vis OSS), the more you’ll rely on institutionalized knowledge moving forward. With OSS, that pool will run deep. With Big Cloud, it might be less, but there will still be some, because components are highly configurable. While it may be a non-issue now, it could be a showstopper down the road. We’ve heard of clients who built in-house and due to internal frustrations, the technical resource who built the solution left the company (they didn’t share why exactly). No one on the team had the knowledge necessary to take over and keep the platform performant. Even if a succession plan was in place, the complexity of such a kludge makes a seamless transition unlikely. While countless dollars had been invested in this path, due to the lack of knowledge transfer, and the unanticipated LOE to maintain it, the entire platform was scrapped. Ouch.
This is just one example, and we are dealing with humans so changes in staff are to be expected (AI to run your AI anyone? Maybe not a great idea…yet). Further driven by the shortage of data science and ml engineer talent, staff departures are not just to be expected, but should be planned for. The average tenure of a data scientist is just 1.75 years, and with an expected salary increase of 14% for each job hop 1, you can see why moving on is easy with even the slightest discomfort in work environment. Just because technical practitioners are traditionally thought of as wallflowers it doesn’t mean they don’t have a parachute and are ready to jump.
Solution: OSS and big cloud are great, but plug in established, composable commercial solutions for mission-critical functions (e.g., model deployment) that are standardized and have robust support. Plan for team departures even for the most crucial of roles and know they’ll take institutional knowledge with them, so position against this as you assemble ML infrastructure & workflows.
Well, I promised you three, but I always like to overdeliver, so here’s a *** BONUS *** fourth consideration. Enjoy!
4. Lower Upfront Costs = Higher Long-Term Overhead
Free. Just look at that word. If you pay attention to your body, you probably feel a slight chill, vibration, or other sensation as endorphins are released into your bloodstream. Whatever it is, it is palpable. With the body’s proclivity for chemical sensations, it’s no wonder that free “just feels good.” So beyond the tangible benefits of gaining control of editable source code and not paying a dime for it, there are other factors at play that justify going the free route. Now, let’s turn this around, someone on the street offers you a free e-bike. If your Spidey sense doesn’t start tingling, then I’ve got some swamp land in Florida I’d like to sell you. But seriously, 99 out of 100 people will respond with the line “what’s the catch?” And so it goes with OSS, as with “free,” there’s always a catch. Most people think they understand the tacit compromise that they are getting into – “sure, no direct support and minimal documentation, with user groups the only semi-reliable recourse for overcoming obstacles. “I got this. Where do I sign?” But the downstream costs – temporal, financial, and beyond can be staggering.
A. Time – The expense of a commercial solution may look steep, but if you’ve ever been at the n’th hour near a deadline (say cramming for finals, or beating a contract deadline), then you know that the price of time is precious and invaluable. What you wouldn’t pay for more time. The tradeoff of going it on your own may be worth anteing some time in the near term, but if you knew upfront that it could cost your AI/ML program a year or more would you make the same decision? Probably not. And of course, you did your research on each OSS solution (well, your team did it via proxy, but they seemed really excited about it and their argument was compelling – granted you didn’t understand ALL the technospeak. Oh, and we didn’t really explore OSS cross-tool compatibility). Due to the complicated nature of ML, data engineering, pipelines, etc. it’s what you don’t know that you don’t know that can cost you (now where have I heard that?!?).
B. Business Value – The promise of AI/ML when appropriately realized is to deliver true business value, be it profits, savings, efficiencies, learnings, or convenience just to name a few. The longer it takes you to “figure out” ML, the less business value you will attain. This could mean missing out on massive profits, especially if you aren’t first…
C. Competitive Advantage – Perhaps you’ve heard of the phrase “the quick and the dead.” So it goes in AI/ML, which, at its apex, provides a generational, not incremental, leap in capabilities and value. If your competitors are quick to get ML “right” this could be catastrophic to your business.
Solution: As part of your planning phase, be thoughtful about where it makes sense to spend in your AI/ML program, not just money, but also precious time, and if you can afford to give a competitive head start. For example, it’s always best to invest in-house in building your models to shelter IP. But does it really make sense to grow support staff for the model delivery mechanism, which will only grow (bloat) as your model library grows? Only you can decide this.
Conclusion: The New Best Practice “Hybrid” Approach
Now that we’ve taken this walk together, let’s explore a bit more why the hybrid approach is the new normal. If I haven’t convinced you already, let me give you some more anecdotal information. Big cloud players, like AWS have a solution for every possible function in any ML workflow. However, this all-in-one approach isn’t filling the needs of savvy, battle-hardened data scientists and ml engineers. In fact, we have been contacted by big cloud regarding a partnership specifically because their customers are telling them that they want the freedom to choose the best point solution for a specific problem even if it extends outside of the big cloud walled garden. Herein enters “Composability,” the concept of a modular ML stack wherein solutions can be swapped out without impacting the constituent neighbor tools or functionality. This is a win-win-win for all. Practitioners can use the best tool for the job even if their vendor-locked to big cloud. Big cloud gets to keep customers with wandering eyes. And smaller players with better capabilities get introduced into workflows, resulting in the absolute best-in-class solution for the end-user. Now that you are equipped with this “best practice” it is up to you to apply it. And remember, it’s no secret that two steps forward may require one step back. Happy ML’ing!
Notes:
About Datatron
Datatron is a flexible and composable MLOps platform that helps businesses deploy, catalog, manage, monitor, & govern ML models in production (on-prem, in any cloud, or integrated feature-by-feature via our API). Datatron is entirely vendor, library, and framework agnostic and supports models built on any stack, including AWS, Azure, GCP, SAS, H2O, Python, R, Scikit-Learn, Tensor-Flow, and more. Whether you are just getting started in MLOps, or want to remedy or supplement your homegrown solution, Datatron is the answer. Datatron is Reliable AI™.