What is Model Drift?
Model Drift (also known as model decay) refers to the degradation of a model’s prediction power due to changes in the environment, and thus the relationships between variables. Referring to the example above, changes in the presentation of spam emails would cause fraudulent detection models created several years ago to degrade.
Types of Model Drift
There are three main types of model drift:
- Concept drift
- Data drift
- Upstream data changes
Concept drift is a type of model drift where the properties of the dependent variable changes. The fraudulent model above is an example of concept drift, where the classification of what is ‘fraudulent’ changes.
Data drift is a type of model drift where the properties of the independent variable(s) change(s). Examples of data drift include changes in the data due to seasonality, changes in consumer preferences, the addition of new products, etc…
Upstream data changes refer to operational data changes in the data pipeline. An example of this is when a feature is no longer being generated, resulting in missing values. Another example is a change in measurement (eg. miles to kilometers).
How to Detect Model Drift
Measuring the Accuracy of the Model
The most accurate way to detect model drift is by comparing the predicted values from a given machine learning model to the actual values. The accuracy of a model worsens as the predicted values deviate farther and farther from the actual values.
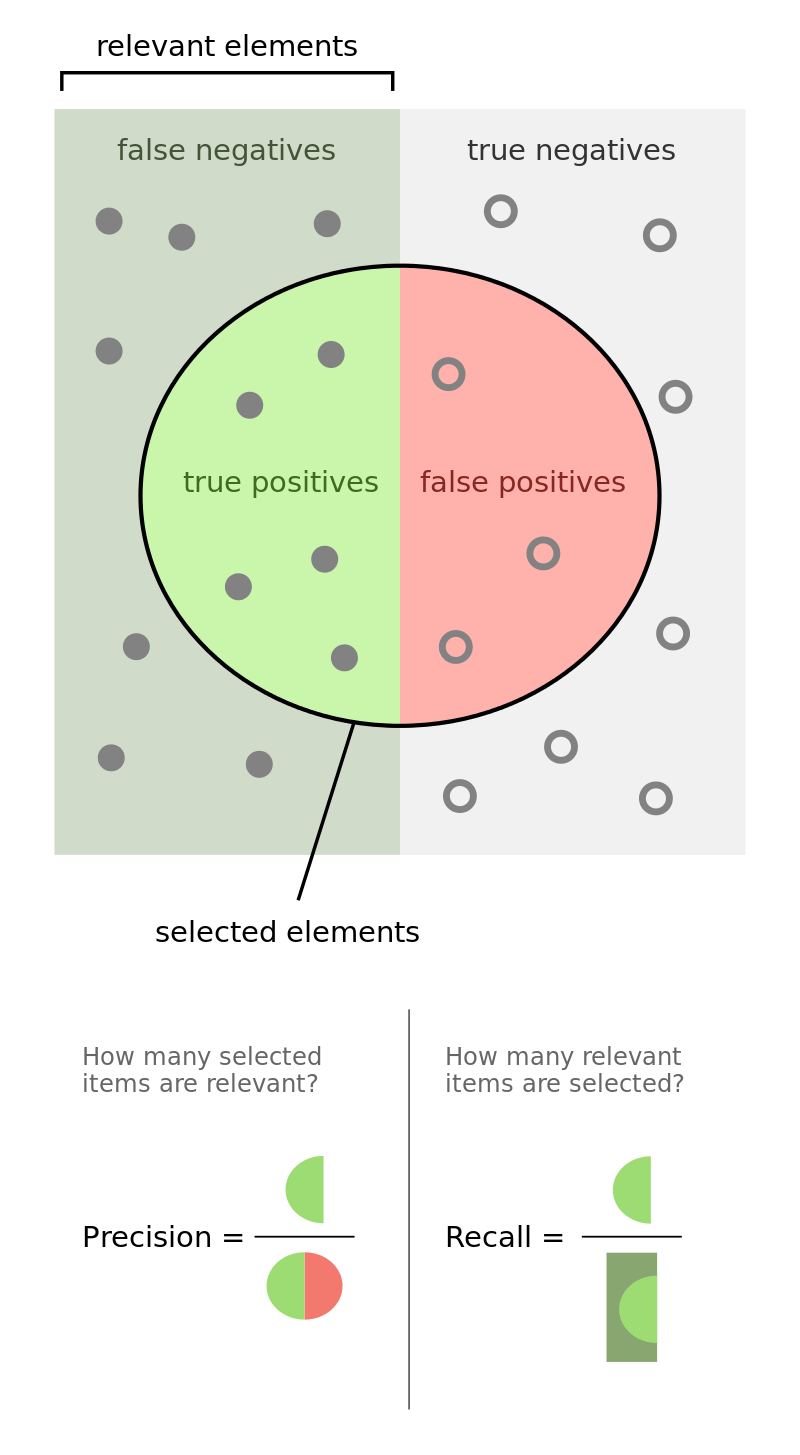
A common metric used to evaluate the accuracy of a model among data scientists is the F1 score, mainly because it encompasses both the precision and recall of the model ( See below for a visual representation of precision and recall). That being said, there are a number of metrics that are more relevant than others depending on the situation. For example, type 2 errors would be extremely important for a cancer-tumor image recognition model. Thus, when a specified metric falls below a given threshold, you’ll know that your model is drifting!
Other Methods to detect Model Drift
Sometimes monitoring the accuracy of a model isn’t always possible. In certain instances, it becomes much harder in obtaining the predicted and actual paired data. For example, imagine a model that predicts the net income of a public firm. This means that you would only be able to measure the accuracy of the model’s predictions of net income 4 times a year from the firm’s quarterly earnings reports. In the case where you aren’t able to compare predicted values to actual values, there are other alternatives that you can rely on:
- Kolmogorov-Smirnov (K-S) test: The K-S test is a nonparametric test that compares the cumulative distributions of two data sets, in this case, the training data and the post-training data. The null hypothesis for this test states that the distributions from both datasets are identical. If the null is rejected then you can conclude that your model has drifted.
- Population stability Index (PSI): The PSI is a metric used to measure how a variable’s distribution has changed over time. It is a popular metric used for monitoring changes in the characteristics of a population, and thus, detecting model decay.
- Z-score: Lastly, you can compare the feature distribution between the training and live data using the z-score. For example, if a number of live data points of a given variable have a z-score of +/- 3, the distribution of the variable may have shifted.
How to Address Model Drift
Detecting model drift is only the first step — the next step is addressing model drift. There are two main methods in doing so.
The first is to simply retrain your model in a scheduled manner. If you know that a model degrades every six months, then you may decide to retrain your model every five months to ensure that the model’s accuracy never falls below a certain threshold
Another way to address model drift is through online learning. Online learning simply means to make a machine learning model learn in real time. It does this by taking in data as soon as it becomes available in sequential order rather than training the model with batch data.
Overall, Detecting Model Drift is hard
The truth is that detecting model drift is hard and there’s no universal blueprint to detect and address model drift.
Now imagine having to detect model drift but for a hundred or even a thousand machine learning models. It almost sounds impossible. If this describes a problem that you’re facing, there are some amazing solutions out there like Datatron.
Here at Datatron, we offer a platform to govern and manage all of your Machine Learning, Artificial Intelligence, and Data Science Models in Production. Additionally, we help you automate, optimize, and accelerate your Machine Learning models to ensure they are running smoothly and efficiently in production — To learn more about our services be sure to Book a Demo.
Follow Datatron on Twitter and LinkedIn!
Thanks for reading!