This quote was by a Greek philosopher named Heraclitus, and it’s such an interesting quote because it’s unironically true. The term ‘constant is defined as occurring continuously over a period of time, and so, you could say that change is perpetual. This poses a problem for machine learning models, as a model is optimized based on the variables and parameters in the time that it was created. A common and sometimes incorrect assumption made while developing a machine learning model is that each data point is an independent and identically distributed (i.i.d) random variable.
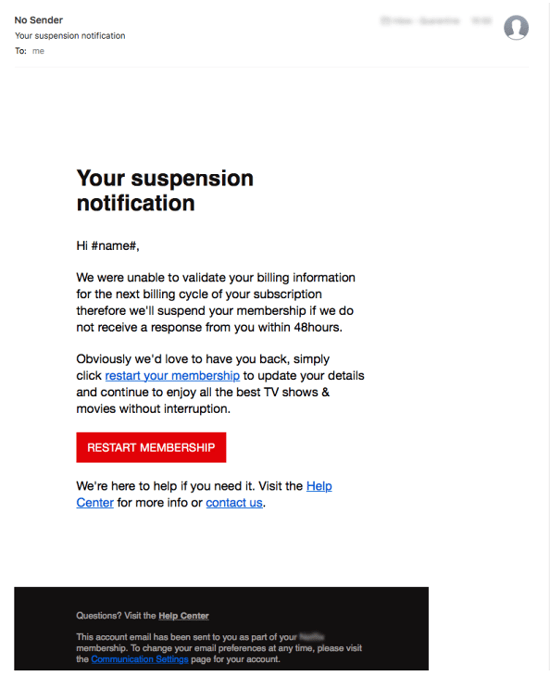
Imagine a classification model created to detect phishy emails (spam emails) created several years ago. Back then, spam emails would look something like this:
You could tell that this is a spam email because it includes an unrealistic lump sum of money being offered ($4.8 million USD), it includes a contact within the email, and it asks you to follow the instructions urgently, or “as soon as you read this email.”
Times have changed since then, and scammers are creating more sophisticated and realistic emails that make it harder to differentiate. Here’s an example of a more recent phishy email:
Notice how different this spam email is compared to the one several years ago. Do you think that the fraudulent detection model created several years ago would be able to classify this email correctly? Probably not because the presentation of phishy emails has changed and models don’t like change. One of the main assumptions when creating a model is that future data will be similar to past data used to build the model.
This is an example of model drift. In this article, you’ll learn what model drift is, the types of model drift, how to detect model drift, and how to address it.
Infographic
MLOps Maturity Model [M3]
In this Infographic, you’ll learn:
The FIVE stages of maturity in Machine Learning Operations, i.e., MLOps
Why DevOps is not the same for ML as it is for software, and why MLOps is needed
The ideal teams, stacks, and features to look for to reach Maturity in your ML program
Learn why some companies succeed, while others struggle in AI/ML by seeing the signatures of success across Ideation, Team, Stack, Process, & Outcome in this informative (Hi-res) Infographic.
Infographic: MLOps Maturity Model [M3]
What is Model Drift?
Model Drift (also known as model decay) refers to the degradation of a model’s prediction power due to changes in the environment, and thus the relationships between variables. Referring to the example above, changes in the presentation of spam emails would cause fraudulent detection models created several years ago to degrade.
Types of Model Drift
There are three main types of model drift:
Concept drift
Data drift
Upstream data changes
Concept drift is a type of model drift where the properties of the dependent variable changes. The fraudulent model above is an example of concept drift, where the classification of what is ‘fraudulent’ changes.
Data drift is a type of model drift where the properties of the independent variable(s) change(s). Examples of data drift include changes in the data due to seasonality, changes in consumer preferences, the addition of new products, etc…
Upstream data changes refer to operational data changes in the data pipeline. An example of this is when a feature is no longer being generated, resulting in missing values. Another example is a change in measurement (eg. miles to kilometers).
How to Detect Model Drift
Measuring the Accuracy of the Model
The most accurate way to detect model drift is by comparing the predicted values from a given machine learning model to the actual values. The accuracy of a model worsens as the predicted values deviate farther and farther from the actual values.
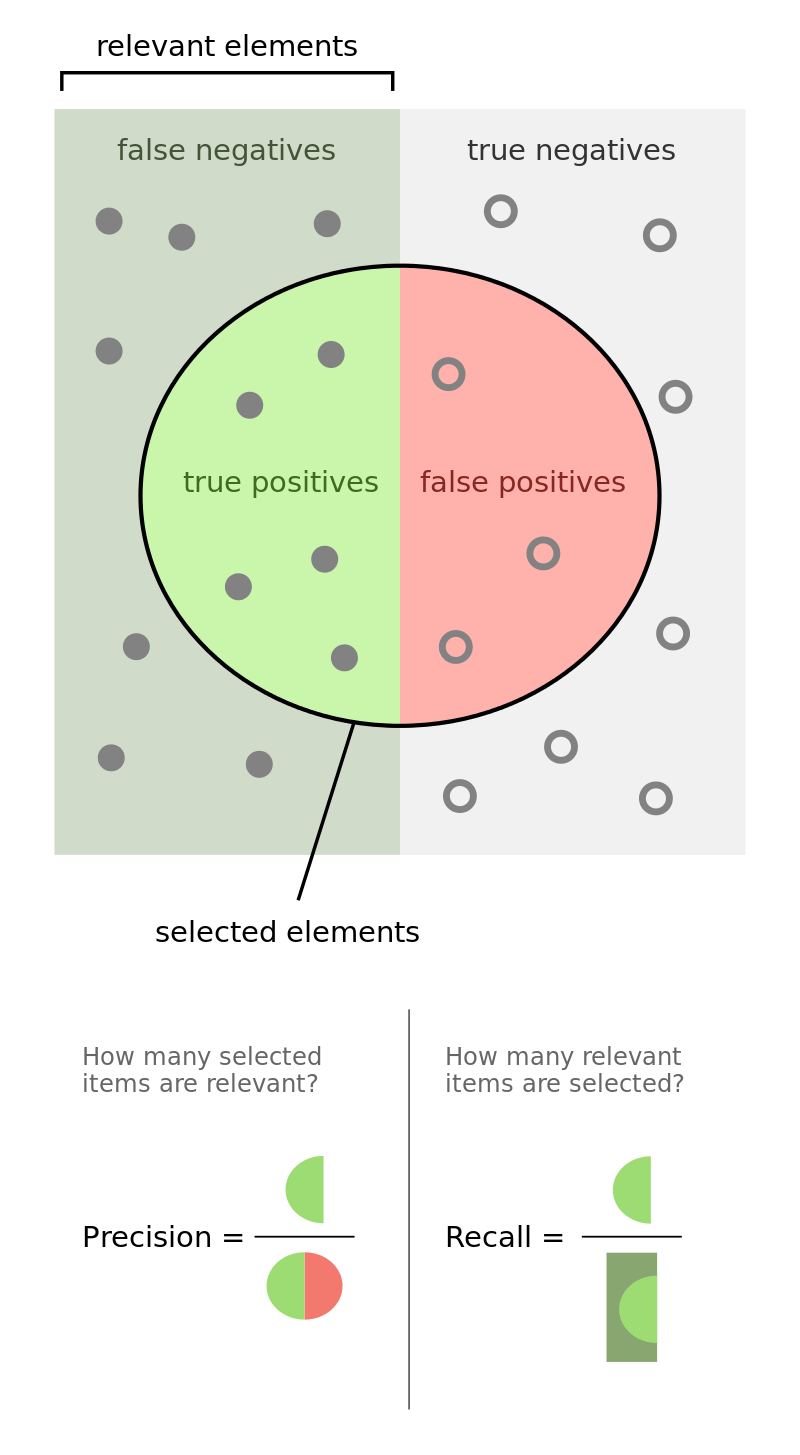
A common metric used to evaluate the accuracy of a model among data scientists is the F1 score, mainly because it encompasses both the precision and recall of the model ( See below for a visual representation of precision and recall). That being said, there are a number of metrics that are more relevant than others depending on the situation. For example, type 2 errors would be extremely important for a cancer-tumor image recognition model. Thus, when a specified metric falls below a given threshold, you’ll know that your model is drifting!
Other Methods to detect Model Drift
Sometimes monitoring the accuracy of a model isn’t always possible. In certain instances, it becomes much harder in obtaining the predicted and actual paired data. For example, imagine a model that predicts the net income of a public firm. This means that you would only be able to measure the accuracy of the model’s predictions of net income 4 times a year from the firm’s quarterly earnings reports. In the case where you aren’t able to compare predicted values to actual values, there are other alternatives that you can rely on:
Kolmogorov-Smirnov (K-S) test: The K-S test is a nonparametric test that compares the cumulative distributions of two data sets, in this case, the training data and the post-training data. The null hypothesis for this test states that the distributions from both datasets are identical. If the null is rejected then you can conclude that your model has drifted.
Population stability Index (PSI): The PSI is a metric used to measure how a variable’s distribution has changed over time. It is a popular metric used for monitoring changes in the characteristics of a population, and thus, detecting model decay.
Z-score: Lastly, you can compare the feature distribution between the training and live data using the z-score. For example, if a number of live data points of a given variable have a z-score of +/- 3, the distribution of the variable may have shifted.
How to Address Model Drift
Detecting model drift is only the first step — the next step is addressing model drift. There are two main methods in doing so.
The first is to simply retrain your model in a scheduled manner. If you know that a model degrades every six months, then you may decide to retrain your model every five months to ensure that the model’s accuracy never falls below a certain threshold
Another way to address model drift is through online learning. Online learning simply means to make a machine learning model learn in real time. It does this by taking in data as soon as it becomes available in sequential order rather than training the model with batch data.
Overall, Detecting Model Drift is hard
The truth is that detecting model drift is hard and there’s no universal blueprint to detect and address model drift.
Now imagine having to detect model drift but for a hundred or even a thousand machine learning models. It almost sounds impossible. If this describes a problem that you’re facing, there are some amazing solutions out there like Datatron.
Here at Datatron, we offer a platform to govern and manage all of your Machine Learning, Artificial Intelligence, and Data Science Models in Production. Additionally, we help you automate, optimize, and accelerate your Machine Learning models to ensure they are running smoothly and efficiently in production — To learn more about our services be sure to Book a Demo.
The FIVE stages of maturity in Machine Learning Operations, i.e., MLOps
Why DevOps is not the same for ML as it is for software, and why MLOps is needed
The ideal teams, stacks, and features to look for to reach Maturity in your ML program
Learn why some companies succeed, while others struggle in AI/ML by seeing the signatures of success across Ideation, Team, Stack, Process, & Outcome in this informative (Hi-res) Infographic.
Datatron continues to lead the way with simplifying data scientist workflows and delivering value from AI/ML with the new JupyterHub integration as part of the “Datatron 3.0” product release.
Success Story: Global Bank Monitors 1,000’s of Models On Datatron
A top global bank was looking for an AI Governance platform and discovered so much more. With Datatron, executives can now easily monitor the “Health” of thousands of models, data scientists decreased the time required to identify issues with models and uncover the root cause by 65%, and each BU decreased their audit reporting time by 65%.
Success Story: Domino’s 10x Model Deployment Velocity
Domino’s was looking for an AI Governance platform and discovered so much more. With Datatron, Domino’s accelerated model deployment 10x, and achieved 80% more risk-free model deployments, all while giving executives a global view of models and helping them to understand the KPI metrics achieved to increase ROI.
AI/ML Executive need more ROI from AI/ML? Data Scientist want to get more models into production? ML DevOps Engineer/IT want an easier way to manage multiple models. Learn how enterprises with mature AI/ML programs overcome obstacles to operationalize more models with greater ease and less manpower.