
Being a Data Scientist in the Modern Era
Traditionally, being a Data Scientist is regarded as a domain exclusive to some people who understand mathematics and statistics. But this will change in the new era.
For the purposes of this post, I will use a large display publisher like Oath (Yahoo! + Aol). Typically, the publisher needs to decide what ad to display in a particular placement in order to maximize conversion, revenue, or margin. This is done on the fly and involves signals from the publisher, the network, the advertiser, and the ad.
The Data Science process primarily consists of three stages:
- Discovery
- Production
- Evaluation and Optimization
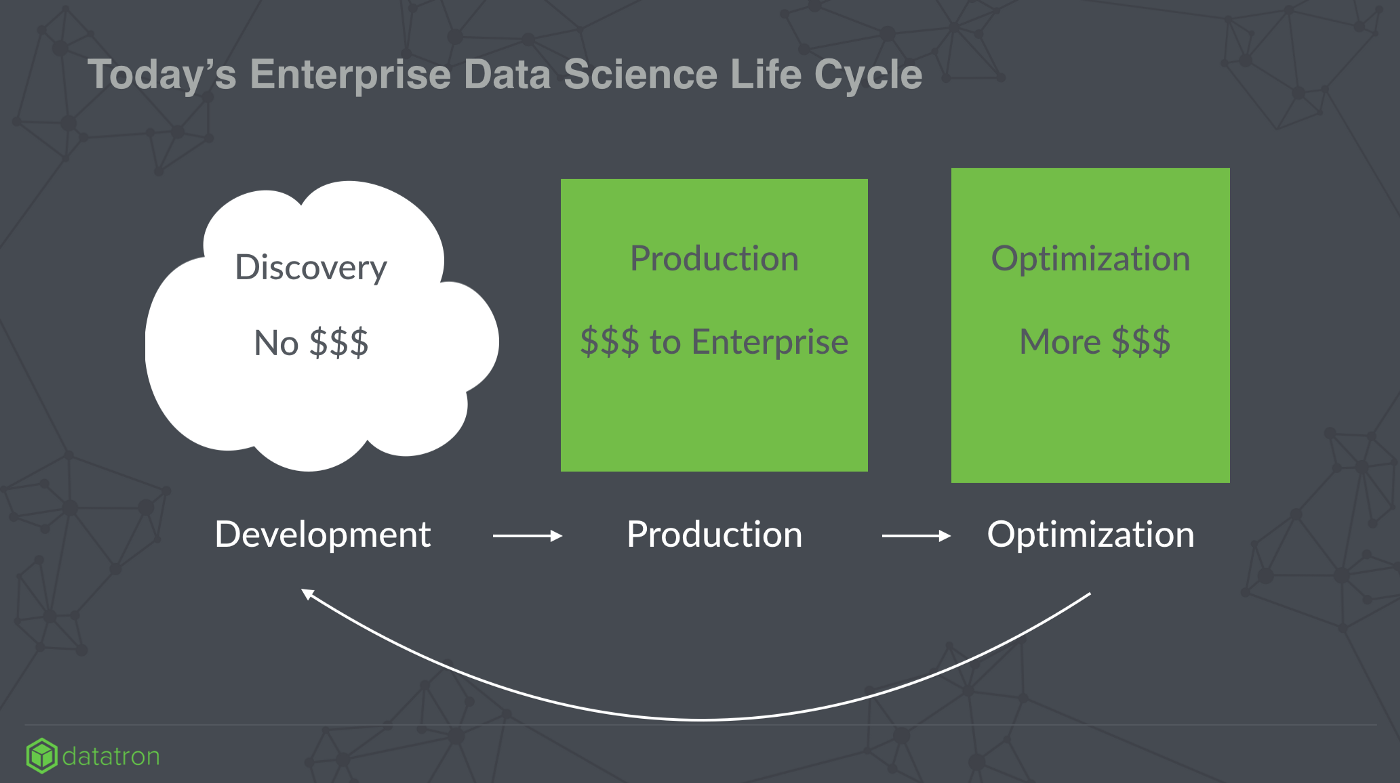
Discovery
In the discovery phase, a data scientist seeks to understand if the piles of data produced by the enterprise contain any signal or they are tasked with validating hypotheses from a business user or data analyst.
This is the place where the data scientist needs to mine through tons of ore and find the essential (gold) data from it. At this stage, the data scientist interacts with other data science team members to share findings, algorithms, models, etc. Though unlikely, perhaps, they also share data sets that are already usable by a model and the wrangling process of “who has which data” across the company and outside. That said, all of this data is typically historical.
The data scientist then builds the initial set of features for a model s/he thinks will bring value to the company. The most important activities for a data scientist are data discovery, data cleansing, data normalization, and algorithm discovery. Typically, this is always done with a static, historical data set. The data wrangling phase of data discovery, data cleansing, and data normalization can be tedious, cyclic, repetitive. Any automation and automation tools in this phase make the lives of the data team immensely productive and joyful.
Notebooks built on Jupyter kernel are the most commonly used tools during the discovery phase. At the end of this process, a data scientist will have many notebooks where the code to build several versions of the model is kept.
Typically, the models built at this stage are off-line, far from a production environment where they could cause material damage. They are built in a vacuum and have no monetary value.
Production
Once a data scientist builds a model, the model needs to be deployed to production to test it on live production traffic. This is where the model has $$$ impact to the Enterprise.
For instance, the model built for ad placement in the discovery will be deployed in production, to understand whether it impacts the click-through rate or not.
This stage involves heavy cross-team activity. The teams involved are Data Science, Data Engineering (or Engineering), DevOps.
Here are the roles played by them.
Data Science: Architect features, algorithm, train and build the machine learning model on the data lake
Data Engineering: Deploy the model given by data science to production. Make sure the model gets data from the sources, deploy model, serve the model, etc.
DevOps: Make sure the model scales, build rollback policy, add additional data sources, etc.
In this stage, the following are the biggest challenges:
- Lot of duplicated work
- Hiring data science talent is hard
- Stand-alone pipelines are built by Engineering team(s)
- We need to iterate on the model multiple times to optimize it.
- No standard framework used to share data sets, features, models, etc.
- Scaling and deployment of models
- It’s all a black box. No standard way to detect the root cause of badly behaving models from bad data to features.
Evaluation
The last process is evaluating the model. This is where you take the decision whether to push the model to the whole live production or tweak the model to make it better. Often, a model is associated with a performance KPI metric that judges the quality of the model.
Typically, as in A/B testing, a model is put on a small percentage of traffic, check how the performance KPI metric is and then decide to either increase the traffic or stop it. Some examples of the KPI performance metrics are user conversion rate, click-through rate, etc.
Evaluating the model is often considered as “post mortem” task and is done manually by the data scientist.
In this stage, data scientists and data engineers collaborate closely. It does not end here though. The cycle repeats, often with duplicated steps. Models can impact almost any aspect of the business, but only if they are in production. Compute advances got us to Big Data. But successful models in production bring us to the new era. Much like how communication patterns in an organization reflect the organization’s org chart, successful model deployments in production is a leading indicator of organizational health and productivity. A successful deployment sets in motion the virtuous cycle of model-deploy-lift in revenue.
If you want to supercharge your data teams and/or are interested in understanding more about Data Science process, email us at info@datatron.com.
Thanks for the read!
For more articles, go here!
Here at Datatron, we offer a platform to govern and manage all of your Machine Learning, Artificial Intelligence, and Data Science Models in Production. Additionally, we help you automate, optimize, and accelerate your ML models to ensure they are running smoothly and efficiently in production — To learn more about our services be sure to Request a Demo.